Published April 3, 2026
Warum LLMs selbst bei Temperatur 0 nicht deterministisch sind
5 min read

Kunpeng GUO
CTO
Have questions or want a demo?
We're here to help! Click the button below and we'll be in touch.
Get a Demo
AI Summary by QAnswer
By Kunpeng Guo
Einleitung
Eine weit verbreitete Annahme in der AI-Community ist, dass das Setzen von temperature = 0 einen Large Language Model (LLM)-Aufruf vollständig reproduzierbar macht — führen Sie denselben Prompt zweimal aus und erhalten Sie dieselbe Antwort. In der Praxis ist dies fast nie wahr. Die Variabilität kann subtil oder dramatisch sein, je nach Modell, Infrastruktur und Art des Prompts — aber sie ist vorhanden.
Bei QAnswer haben wir einen strukturierten Benchmark durchgeführt, um dies zu quantifizieren. Wir haben denselben Prompt zehnmal an dasselbe Modell bei temperature 0 gesendet und gemessen, wie oft aufeinanderfolgende Antworten byteweise identisch waren. Die Ergebnisse sind bemerkenswert.
Benchmark-Ergebnisse
Wir haben fünf Modelle mit drei verschiedenen Prompts getestet. Jedes Modell erhielt 10 gepaarte Ausführungen bei temperature 0 (außer GPT-5, das bei temperature 1 als bewusste Kontrolle getestet wurde). Hier sind die Ergebnisse:
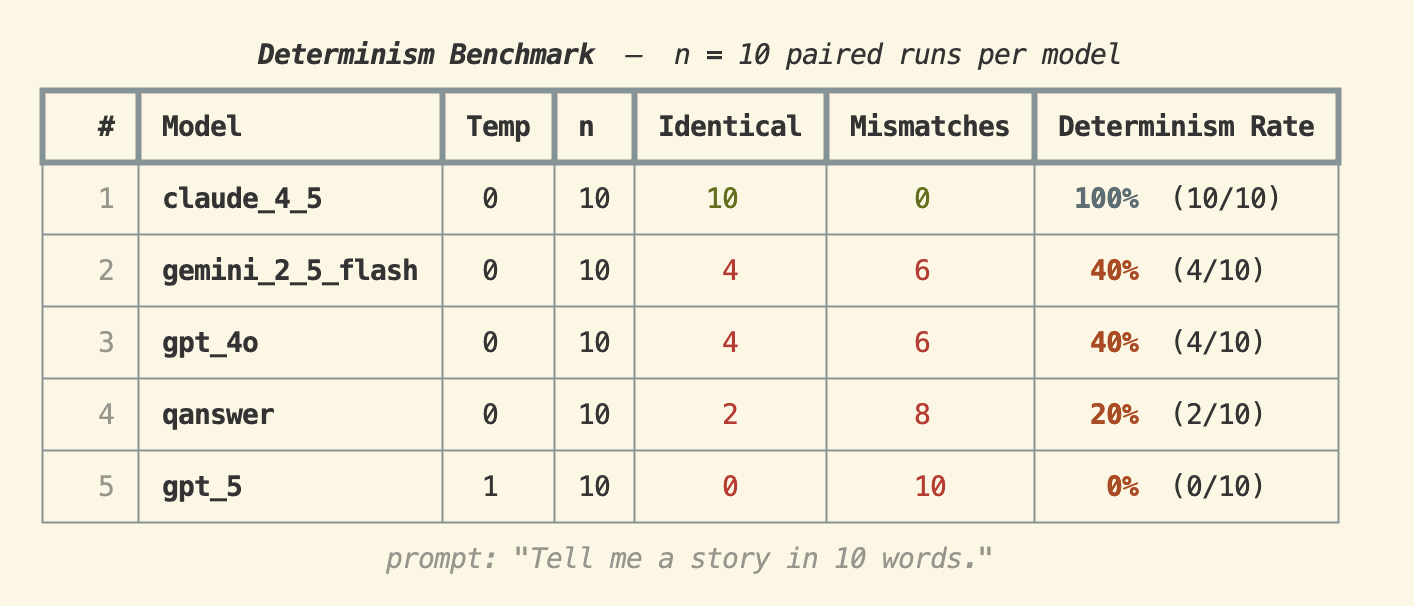
Prompt: "Tell me a story in 10 words."
Claude 4.5 erzielte eine 100%ige Determinismusrate — alle 10 Ausführungen erzeugten identische Ausgaben. GPT-4o und Gemini 2.5 Flash lagen beide bei 40%, während QAnswer 20% erzielte. GPT-5 (bei temperature 1) hatte 0% — was wenig überraschend ist, da eine hohe temperature ausdrücklich darauf ausgelegt ist, Zufälligkeit einzuführen.
Prompt: "Hello, who are you?"
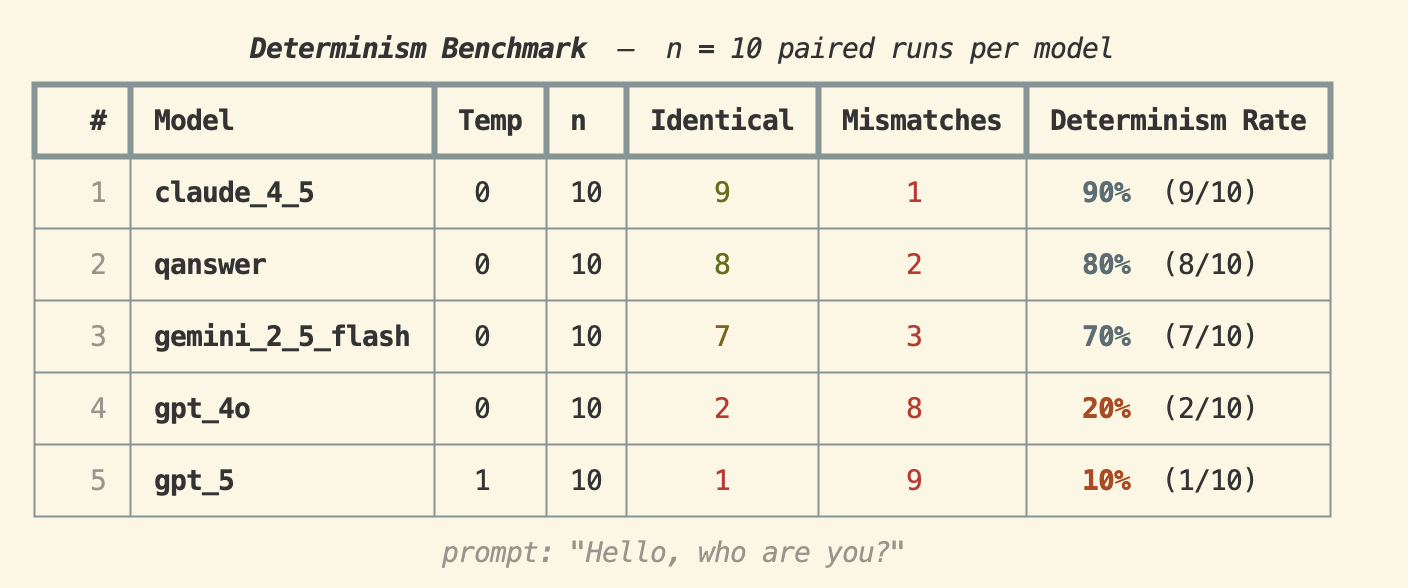
Claude 4.5 fiel auf 90%, und interessanterweise stieg QAnswer auf 80% — zweiter Platz. Gemini 2.5 Flash erreichte 70%, während GPT-4o stark auf 20% fiel. GPT-5 erzielte 10% selbst bei temperature 1, was auf eine minimale strukturelle Konsistenz hindeutet.
Prompt: "Explain me prime numbers like I am a 5 year old."
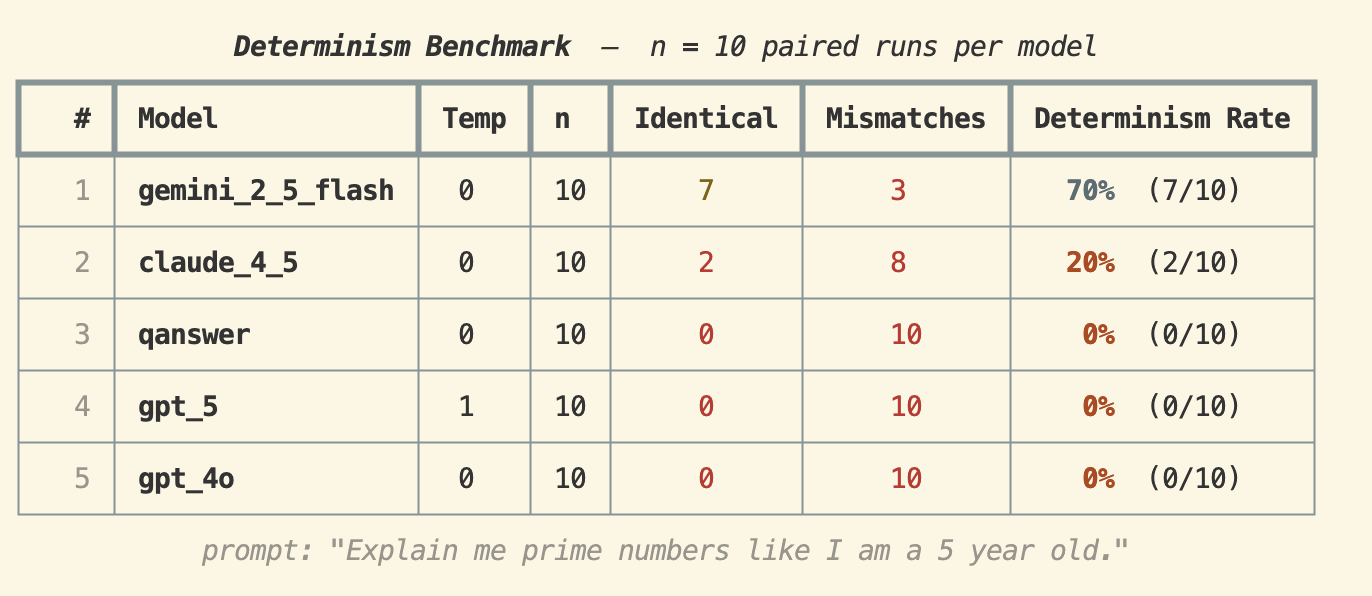
Dieser längere, offene Prompt zeigt, wie schnell der Determinismus zusammenbricht. Gemini 2.5 Flash führte mit 70%, Claude 4.5 fiel auf 20%, und QAnswer, GPT-5 sowie GPT-4o erzielten alle 0%. Wenn der Prompt mehr Tokens und mehr kreatives Denken erfordert, ist die Reproduzierbarkeit im Wesentlichen verschwunden — selbst bei temperature 0.
Warum Passiert Das? Sechs Grundursachen
Die Benchmark-Ergebnisse sind kein Bug — sie spiegeln grundlegende Eigenschaften wider, wie moderne LLMs gebaut und eingesetzt werden. Hier sind die sechs Hauptgründe:
1. Einschränkungen der Gleitkomma-Präzision
Computer stellen reelle Zahlen mit Gleitkommaformaten endlicher Präzision dar. Bei den Milliarden von arithmetischen Operationen in einem Forward-Pass summieren sich winzige Rundungsfehler und können sich durch nachfolgende Token-Vorhersagen fortpflanzen. Selbst eine Differenz von einem einzelnen Bit in einer Zwischenaktivierung kann das Top-1-Token kippen, wenn zwei Kandidaten nahezu gleiche Wahrscheinlichkeiten haben.
2. Parallelismus und Hardware-Variabilität
LLMs laufen auf GPUs oder TPUs, die Tausende von Operationen gleichzeitig ausführen. Gleitkomma-Addition ist nicht perfekt assoziativ — (a + b) + c kann von a + (b + c) in der Gleitkomma-Arithmetik abweichen, wenn Rundungen im Spiel sind. Eine unterschiedliche Planung paralleler Threads oder das Ausführen desselben Modells auf verschiedenen GPU-Architekturen (z.B. A100 vs. H100 vs. T4) kann subtil unterschiedliche Summen und damit unterschiedliche Token-Wahrscheinlichkeiten erzeugen.
3. Tie-Breaking beim Dekodieren
Temperature 0 bedeutet, dass das Modell immer das wahrscheinlichste nächste Token auswählt — aber was passiert, wenn zwei Tokens nahezu identische Wahrscheinlichkeiten haben? Die Tie-Breaking-Regel ist möglicherweise nicht konsistent über Anfragen hinweg, und Sampling-Parameter wie top_k oder top_p können in manchen Implementierungen noch aktiv sein und still Stochastizität wieder einführen, selbst wenn die temperature auf null gesetzt ist.
4. Mixture-of-Experts (MoE)-Architekturen
Viele modernste Modelle (einschließlich einiger Versionen von GPT-4 und Gemini) verwenden Mixture-of-Experts-Schichten, bei denen ein Router jedes Token an ein oder mehrere spezialisierte Teilnetzwerke sendet. Bei der Batch-Inferenz — bei der Ihre Anfrage zusammen mit den Anfragen anderer Nutzer verarbeitet wird — konkurrieren Tokens aus verschiedenen Sequenzen um dieselben Expert-Slots. Die Routing-Entscheidung für Ihr Token kann daher davon abhängen, was sich sonst noch im Batch befindet, was eine Variabilität auf Anfrage-Ebene einführt, die völlig außerhalb Ihrer Kontrolle liegt.
5. Nicht-Deterministische Framework-Operationen
Deep-Learning-Frameworks wie PyTorch und TensorFlow optimieren auf Geschwindigkeit, nicht auf Reproduzierbarkeit. Operationen wie parallele Reduktionen, Atomics auf dem gemeinsamen GPU-Speicher und CUDA-Kernel-Starts können bei verschiedenen Ausführungen in einer anderen Reihenfolge ablaufen. Sofern das Framework nicht explizit für vollständigen Determinismus konfiguriert ist (was typischerweise eine erhebliche Leistungseinbuße mit sich bringt), führen diese Operationen auf Hardware-Ebene Variationen zwischen Ausführungen ein.
6. Deployment- und Infrastrukturfaktoren
Cloud-gehostete LLM-APIs leiten Anfragen über Cluster von Maschinen weiter, die sich in Hardware-Generation, Treiberversionen oder Modell-Checkpoint-Versionen unterscheiden können. Load-Balancing bedeutet, dass Ihre zwei identischen Anfragen auf verschiedenen physischen Servern landen können. Batching-Strategien — die gleichzeitige Anfragen zusammenfassen, um die GPU-Auslastung zu maximieren — bedeuten, dass sich die genaue Zusammensetzung des Batches mit der Systemlast ändert, was bei MoE-Modellen die Ausgaben direkt beeinflusst und andere indirekt durch die Reihenfolge der Gleitkomma-Summation.
Was Bedeutet Das in der Praxis?
Für die meisten Konversationsanwendungen ist eine leichte Ausgabevarianz bei temperature 0 akzeptabel — der semantische Inhalt der Antwort ist in der Regel stabil, auch wenn die genaue Formulierung abweicht. Für Anwendungsfälle, die eine strikte Reproduzierbarkeit erfordern — automatisierte Pipelines, Audit-Trails, Compliance-Workflows oder deterministische Test-Suites — ist temperature 0 allein jedoch nicht ausreichend.
Wenn Ihre Anwendung wirklich reproduzierbare Ausgaben benötigt, müssen Sie:
- Antworten cachen und das gecachte Ergebnis für wiederholte identische Anfragen ausliefern
- Ein selbst gehostetes Modell auf fester Hardware mit vollständiger Kontrolle über die Batch-Zusammensetzung und die Determinismus-Einstellungen des Frameworks verwenden
- Ihre nachgelagerte Logik so gestalten, dass sie robust gegenüber geringfügigen Ausgabevariationen ist, anstatt exakte Wiederholbarkeit vorauszusetzen
Fazit
Temperature 0 ist eine nützliche Heuristik, um LLM-Ausgaben konsistenter zu machen, aber es ist keine Garantie für Determinismus. Unsere Benchmarks zeigen, dass die realen Determinismusraten stark variieren — von 100% bei kurzen, eingeschränkten Prompts bis zu 0% bei längeren, offenen — und sich je nach Modell und Deployment erheblich unterscheiden.
Dies zu verstehen ist für jeden unerlässlich, der zuverlässige AI-gestützte Anwendungen entwickelt. Bei QAnswer gestalten wir unsere Plattform mit diesen Einschränkungen im Blick und geben Unternehmen die Kontrolle und Transparenz, die sie benötigen, um AI verantwortungsvoll einzusetzen.
Interessiert daran, wie QAnswer Konsistenz und Nachvollziehbarkeit in unternehmensweiten AI-Deployments handhabt? Testen Sie QAnswer kostenlos oder kontaktieren Sie uns unter info@the-qa-company.com.
Back to Blog
The AI platform that works.
Try for free today