Published April 3, 2026
Pourquoi les LLM ne sont pas Déterministes même à Température 0
6 min read

Kunpeng GUO
CTO
Have questions or want a demo?
We're here to help! Click the button below and we'll be in touch.
Get a Demo
AI Summary by QAnswer
By Kunpeng Guo
Introduction
Une hypothèse répandue dans la communauté AI est que définir temperature = 0 rend un appel à un Large Language Model (LLM) entièrement reproductible — exécutez le même prompt deux fois, obtenez la même réponse. En pratique, c'est presque jamais vrai. La variabilité peut être subtile ou dramatique selon le modèle, l'infrastructure et le type de prompt — mais elle est bien présente.
Chez QAnswer, nous avons réalisé un benchmark structuré pour quantifier cela. Nous avons envoyé le même prompt dix fois au même modèle à temperature 0 et mesuré la fréquence à laquelle les réponses consécutives étaient identiques octet par octet. Les résultats sont frappants.
Résultats du Benchmark
Nous avons testé cinq modèles sur trois prompts différents. Chaque modèle a reçu 10 paires d'exécutions à temperature 0 (sauf GPT-5, qui a été testé à temperature 1 comme contrôle délibéré). Voici les résultats :
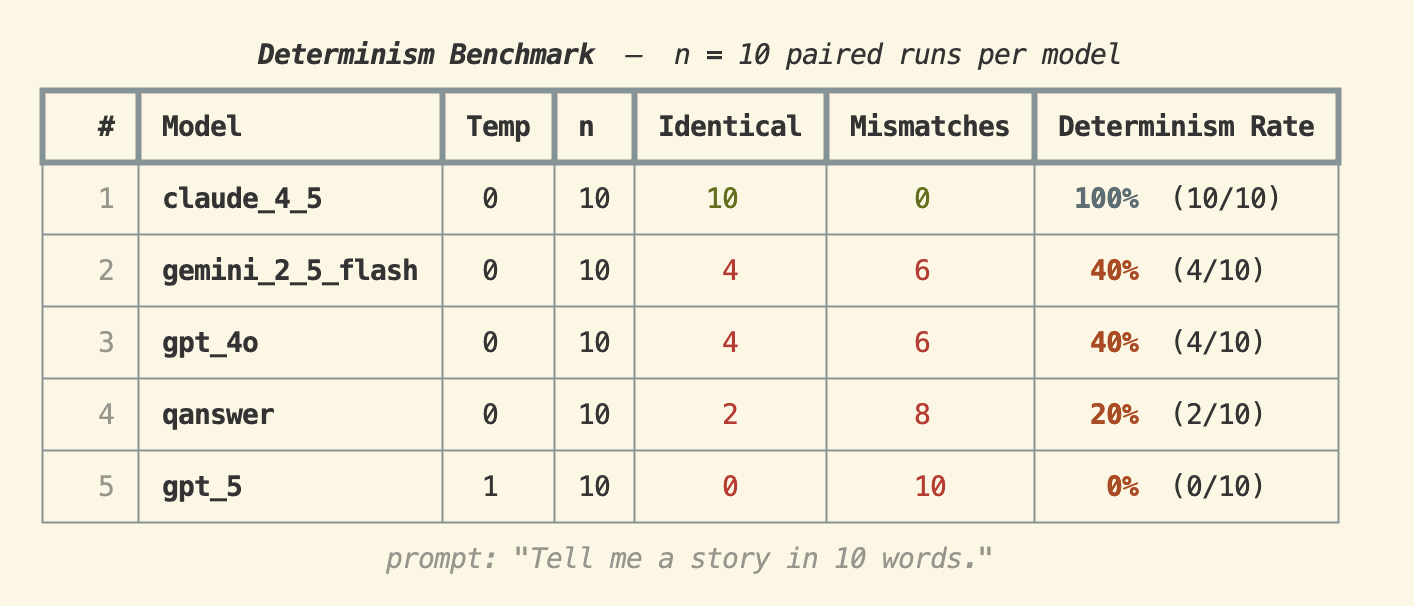
Prompt : "Tell me a story in 10 words."
Claude 4.5 a atteint un taux de déterminisme de 100% — les 10 exécutions ont produit une sortie identique. GPT-4o et Gemini 2.5 Flash ont tous deux obtenu 40%, tandis que QAnswer a obtenu 20%. GPT-5 (à temperature 1) a eu 0% — ce qui n'est pas surprenant, puisqu'une temperature élevée est explicitement conçue pour introduire de l'aléatoire.
Prompt : "Hello, who are you?"
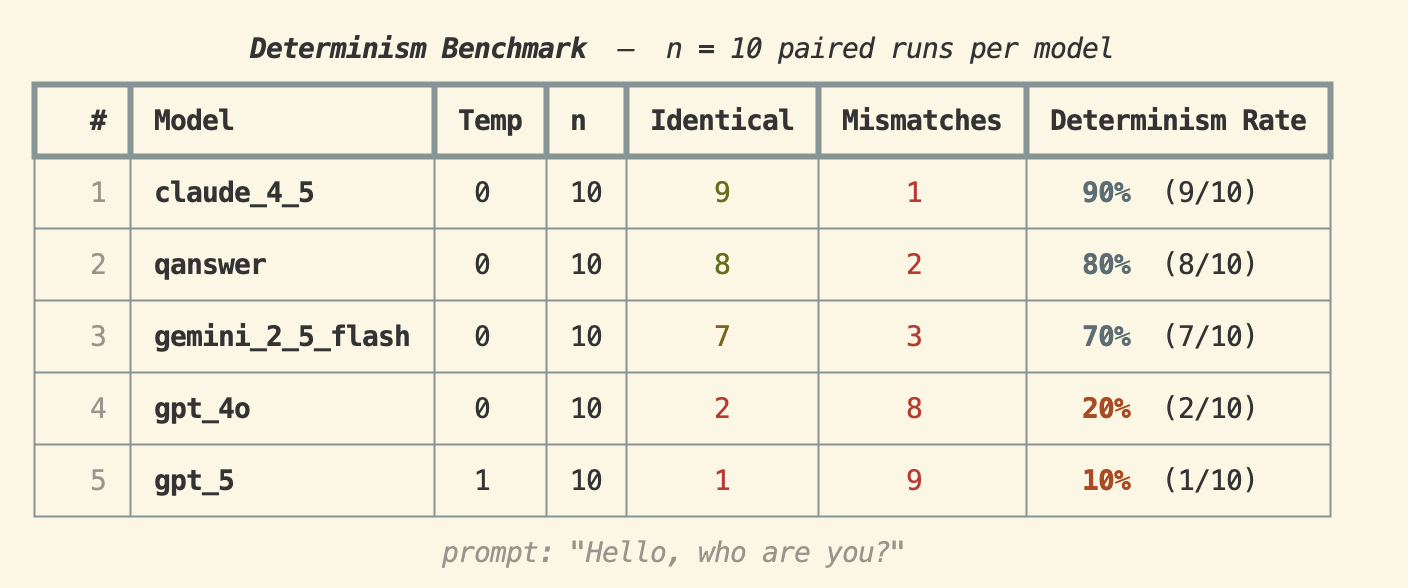
Claude 4.5 est tombé à 90%, et de manière intéressante QAnswer a grimpé à 80% — deuxième place. Gemini 2.5 Flash a atteint 70%, tandis que GPT-4o a chuté fortement à 20%. GPT-5 a obtenu 10% même à temperature 1, suggérant une cohérence structurelle minimale.
Prompt : "Explain me prime numbers like I am a 5 year old."
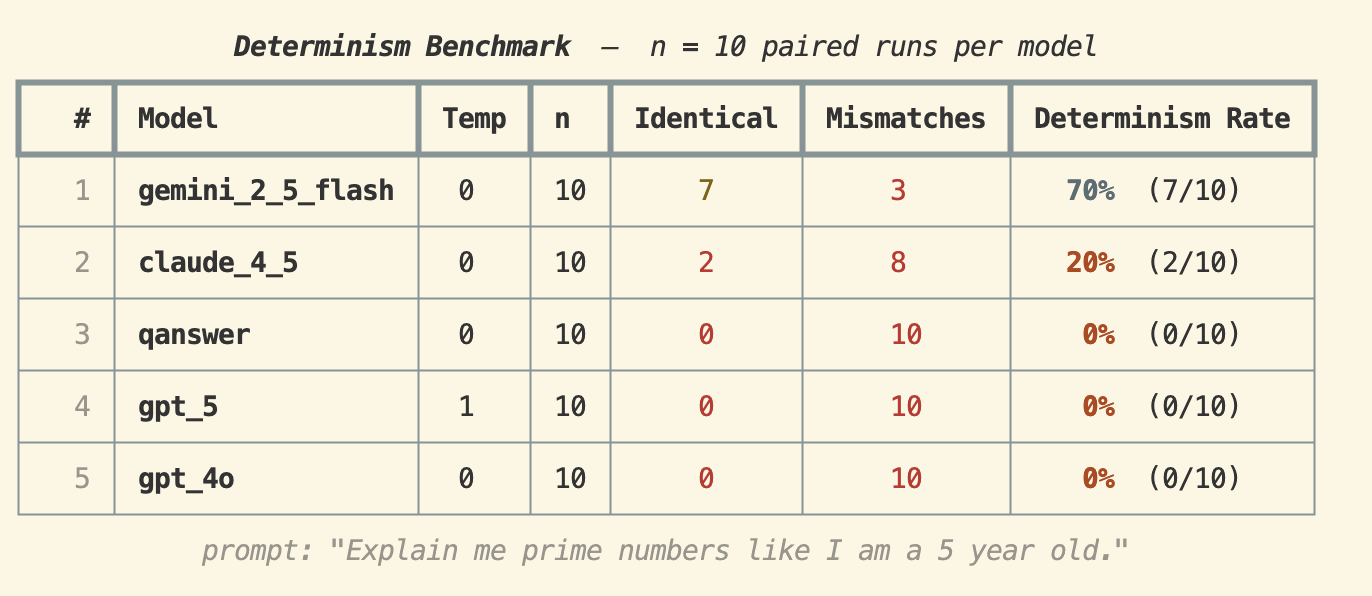
Ce prompt plus long et ouvert révèle à quelle vitesse le déterminisme s'effondre. Gemini 2.5 Flash a mené avec 70%, Claude 4.5 est tombé à 20%, et QAnswer, GPT-5 et GPT-4o ont tous obtenu 0%. Lorsque le prompt nécessite plus de tokens et un raisonnement plus créatif, la reproductibilité disparaît essentiellement — même à temperature 0.
Pourquoi Cela Se Produit-il ? Six Causes Fondamentales
Les résultats du benchmark ne sont pas un bug — ils reflètent des propriétés fondamentales de la façon dont les LLMs modernes sont construits et déployés. Voici les six principales raisons :
1. Limitations de la Précision en Virgule Flottante
Les ordinateurs représentent les nombres réels en utilisant des formats à virgule flottante avec une précision finie. Au cours des milliards d'opérations arithmétiques dans un passage en avant, de minuscules erreurs d'arrondi s'accumulent et peuvent se propager à travers les prédictions de tokens suivantes. Même une différence d'un seul bit dans une activation intermédiaire peut faire basculer le token top-1 lorsque deux candidats ont des probabilités presque égales.
2. Parallélisme et Variabilité Matérielle
Les LLMs s'exécutent sur des GPU ou des TPU qui effectuent des milliers d'opérations simultanément. L'addition en virgule flottante n'est pas parfaitement associative — (a + b) + c peut différer de a + (b + c) en arithmétique à virgule flottante lorsque des arrondis sont impliqués. Une planification différente des threads parallèles, ou l'exécution du même modèle sur différentes architectures GPU (par ex., A100 vs. H100 vs. T4), peut produire des sommes subtilement différentes et donc des probabilités de tokens différentes.
3. Départage des Égalités lors du Décodage
Temperature 0 signifie que le modèle sélectionne toujours le token suivant le plus probable — mais que se passe-t-il lorsque deux tokens ont des probabilités presque identiques ? La règle de départage peut ne pas être cohérente entre les requêtes, et des paramètres d'échantillonnage comme top_k ou top_p peuvent encore être actifs dans certaines implémentations, réintroduisant discrètement de la stochasticité même lorsque la temperature est définie à zéro.
4. Architectures Mixture-of-Experts (MoE)
De nombreux modèles de pointe (dont certaines versions de GPT-4 et Gemini) utilisent des couches Mixture-of-Experts, où un routeur envoie chaque token vers un ou plusieurs sous-réseaux spécialisés. Dans l'inférence par lots — où votre requête est traitée conjointement avec celles d'autres utilisateurs — les tokens de différentes séquences se disputent les mêmes slots d'experts. La décision de routage pour votre token peut donc dépendre de ce qui se trouve dans le lot, introduisant une variabilité au niveau de la requête qui échappe totalement à votre contrôle.
5. Opérations Non-Déterministes des Frameworks
Les frameworks de deep learning comme PyTorch et TensorFlow optimisent pour la vitesse, pas pour la reproductibilité. Des opérations telles que les réductions parallèles, les atomiques sur la mémoire partagée GPU et les lancements de kernels CUDA peuvent s'exécuter dans un ordre différent entre les exécutions. À moins que le framework ne soit explicitement configuré pour un déterminisme complet (ce qui impose généralement une pénalité de performance significative), ces opérations introduisent des variations d'une exécution à l'autre au niveau matériel.
6. Facteurs de Déploiement et d'Infrastructure
Les API LLM hébergées dans le cloud acheminent les requêtes à travers des clusters de machines pouvant différer en génération matérielle, versions de pilotes ou versions de checkpoint de modèle. L'équilibrage de charge signifie que vos deux requêtes identiques peuvent atterrir sur des serveurs physiques différents. Les stratégies de mise en lot — qui regroupent les requêtes simultanées pour maximiser l'utilisation du GPU — signifient que la composition exacte du lot change avec la charge du système, affectant directement les sorties pour les modèles MoE et indirectement les autres via l'ordre de sommation en virgule flottante.
Qu'est-ce que Cela Signifie en Pratique ?
Pour la plupart des applications conversationnelles, une légère variation de sortie à temperature 0 est acceptable — le contenu sémantique de la réponse est généralement stable même lorsque la formulation exacte diffère. Cependant, pour les cas d'usage qui nécessitent une reproductibilité stricte — pipelines automatisés, pistes d'audit, workflows de conformité ou suites de tests déterministes — la temperature 0 seule n'est pas suffisante.
Si votre application nécessite réellement des sorties reproductibles, vous devez :
- Mettre en cache les réponses et servir le résultat mis en cache pour les requêtes identiques répétées
- Utiliser un modèle auto-hébergé sur du matériel fixe avec un contrôle total sur la composition des lots et les paramètres de déterminisme du framework
- Concevoir votre logique en aval pour être robuste aux légères variations de sortie plutôt que de supposer une répétabilité exacte
Conclusion
Temperature 0 est une heuristique utile pour rendre les sorties LLM plus cohérentes, mais ce n'est pas une garantie de déterminisme. Nos benchmarks montrent que les taux de déterminisme dans le monde réel varient considérablement — de 100% sur des prompts courts et contraints à 0% sur des prompts plus longs et ouverts — et diffèrent significativement selon les modèles et les déploiements.
Comprendre cela est essentiel pour quiconque construit des applications fiables basées sur l'AI. Chez QAnswer, nous concevons notre plateforme en tenant compte de ces contraintes, offrant aux entreprises le contrôle et la transparence dont elles ont besoin pour déployer l'AI de manière responsable.
Vous souhaitez savoir comment QAnswer gère la cohérence et la traçabilité dans les déploiements AI en entreprise ? Essayez QAnswer gratuitement ou contactez-nous à info@the-qa-company.com.
Back to Blog
The AI platform that works.
Try for free today